
Contra dados HÁ argumentos, sim!
Dados e fatos são coisas distintas. Tudo vai depender do quanto as informações são confiáveis.
Quando li pela primeira vez sobre a importância dos dados para o marketing – e para a gestão de uma maneira geral – fiquei fascinado. A ideia de tomar decisões baseadas em fatos e não em “achismos” (como muitas vezes acontece) me parecia a mais significativa até aquele momento. Uma grande sacada. E abracei o conceito de “Sistema de Informações de Marketing” jurando amor eterno.
Com o crescimento do marketing digital – sua vastidão de dados disponíveis – por muito tempo achei que todas ações online eram mensuráveis com dados confiáveis. Mas, após 16 anos de convivência diária com os dados, cheguei a conclusão de que a máxima “Contra dados não há argumentos” vai depender muito da confiabilidade dos dados.
Ao me aprofundar no mundo do Data Analytics, descobri a diversidade de etapas de processamentos que os dados passam antes de ficarem prontos para virarem um gráfico bonito. O processo é chamado de ETL: Extração, Tratamento e Carregamento (Load, em inglês). Cada uma dessas etapas pode envolver uma diversas tarefas (automatizadas ou não), fórmulas e junções. E basta um descuido para gerar dados finais imprecisos ou distorcidos.
De que dados estamos falando?
Algo que ficou muito evidente é que nem todas as informações são 100% confiáveis – embora pareçam ser. Não me refiro a informações gritantemente erradas, como o dobro/triplo da informação correta, ou informações de uma fonte que são facilmente comparáveis com outras – como o valor de venda apontado por uma plataforma, que identificamos que está errado só de cruzar com o valor indicado em caixa. Me refiro a indicadores secundários – número de sessões em um site, quantidade de checkouts iniciados em um ecommerce, taxa de interação em uma rede social. Especialmente se só existe uma única fonte acessível de informação ou quando a diferença não é tão significativa.
Nesses casos, a tendência da maioria dos profissionais é não verificar a informação. Mesmo quando se identifica discrepância, a correria profissional e a falta de domínio sobre as origens de dados desencoraja muitas pessoas a confrontar (com provas) os provedores de informações e exigir correção.
Então, sim, há dois tipos de informação: a correta e a que te entregam. E nem sempre elas são iguais.
Confiar desconfiando
Quando comecei a identificar esses fenômenos e ficar “com pé atrás” sobre os dados, comecei a colecionar cases icônicos. Já me deparei com casos de plataforma de relatório de marketing digital fazendo cálculos errados com os dados que recebia ou usando conceitos equivocados nos indicadores que apresentava. E, com isso, acabavam induzindo os usuários a tirar conclusões precipitadas.
No e-commerce, notei certa vez que os dados de rastreamento de origem das conversões (vendas) estava sendo contabilizado de maneira equivocada em uma das platafomas de cómercio eletrônico mais usadas no Brasil. Dava pra ver que muita gente vinha por mídia paga, mas quase todos que convertiam era por tráfego direto. Mas, quando abri chamado, a plataforma de ecommerce negou que estivesse acontecendo problema. Foi necessário conversar com uma série de colegas programadores, fazer testes com data layers (camadas de dados), juntar provas em vídeo para só então – meses depois – eles se convencerem de que estava acontecendo um problema que prejudicava muito quem trabalhava com anúncios.
Um tempo depois, na mesma plataforma, um problema ainda maior: o principal indicador do e-commerce, o de Valor Total de Vendas, tinha um problema metodológico em que contabilizavam certas vendas de um modo (descontando as taxas do intermediador de pagamento) e, outras, de modo distinto (com as taxas), dependendo do meio de pagamento usado. Não havia um padrão nos critérios. E isso não apenas gerou uma insegurança sobre a integridade dos dados como também uma série de problemas com o nosso financeiro, que não conseguia fazer a conciliação de recebíveis.
Mesmo em ERPs – teoricamente, plataformas de gestão empresarial de grande robustez e confiabilidade – já vi alguns erros acontecendo. Algum erro de fórmula há anos atrás que ninguém percebe e vai ficando. Uma atualização de módulo que afeta uma customização antiga e que gera um bug discreto. Até o dia que um gestor apresenta uma informação que deveria bater com a informação de outro setor, mas que não está igual. Aí fica todo mundo com cara daquele meme do John Travolta em Pump Fiction…
Por isso, quando se trava de dados, sigo o ensinamento que meu pai me passou na infância, sobre pessoas estranhas: “confiar desconfiando”.
O caso das redes sociais
Quando comecei a identificar esses fenômenos e ficar “com pé atrás” sobre os dados, comecei a colecionar cases icônicos. Dois deles dizem respeito a relatórios de marketing digital gerados por plataformas bem conhecidas no mercado. Uma nacional e outra do exterior, cujo nome vou omitir, por questões éticas.
Em um dos casos, trabalhava em uma agência e desenvolvíamos uma estratégia de awareness (aproximação com a marca). Um dos indicadores acompanhados era de alcance – que na teoria representa o número de pessoas alcançada por uma campanha ou conjunto de ações. Os números eram expressivos, tanto que um dia notei que já superavam a população da região trabalhada. Olhando nos dados do Meta, os números não batiam com o da plataforma externa – o que era estranho, já que a segunda “puxava” os dados diretamente da primeira. Quando fui falar com o suporte, a resposta me supreendeu: a Meta entregava os dados periodicamente via API, mas, nessa entrega, poderia haver sobreposição de informação. Já no próprio Facebook/Meta, a sobreposição era tratada.
Em resumo, se você viu uma campanha hoje e também viu amanhã, no Meta será indicado apenas um alcance. Já na plataforma externa, haveria a entrega da informação que você viu a campanha hoje e amanhã, e a plataforma vai considerar dois alcances em vez de um. Se você foi impactado de maneira orgânica (gratuitamente pela página ou perfil) e depois de maneira paga (anúncios) essa sobreposição também não será levada em conta. Segundo a plataforma, não havia o que se fazer. Mas também em momento algum eles indicavam essa limitação da precisão dos dados ou alteração nos critérios de contabilização. Milhares de usuários eram induzidos ao erro mostrando dados irreais. E, para a plataforma, estava tudo bem
Em outra plataforma (do exterior) também identifiquei um problema de tratamento de dados: a forma como era calculada a taxa de interação estava errada. Misturavam dados de alcance orgânico com alcance pago, embora o relatório fosse direcionado apenas aos pots orgânicos. Em resumo e usando bom português, misturavam “alhos com bugalhos” e com isso mostravam um valor totalmente equivocado. Depois de uma série de prints, pelo menos o suporte aceitou o caso e o passou para o time de engenharia, que fez as correções.
Todos nós podemos errar
Não pense que pode acontecer apenas com programadores! Você já pode ter gerado informações equivocada e nunca nem percebeu…
Um caso que me deparei e que me deixou pensativo está relacionada ao cálculo do ticket médio.A fórmula geralmente usada para calculá-lo é total vendido dividido pela quantidade de vendas. Bem simples.
Mas veja a seguinte situação: todos os meses você faz um relatório para seu gestor com o ticket médio de cada mês. Você aplicou a fórmula acima e agora tem um excel com os resultados mês a mês. Certo dia, durante uma importante reunião, seu gestor pergunta: “fulano, quanto mesmo é nosso ticket médio?”. O valor mês a mês oscila consideravelmente. Mas você está com a planilha da média mês a mês ao alcance, rapidamente usa a fórmula de média e chega a um valor que parece razoável. Passa pra ele. Aparentemente, tudo certo nessa lógica, certo?
Errado! Veja um caso a seguir. (vou considerar apenas dois meses pra facilitar)
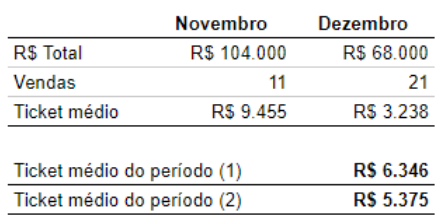
No cálculo 1, foi feito uma média entre o ticket médio de novembro e de dezembro, como no exemplo fictício com seu gestor. Já no calculo 2, foi somado o valor total das vendas no período (equivalente a fazer 104 mil + 68 mil) e dividir pelo total de vendas (11+21=32). Os dois cálculos parecem fazer sentido, certo? Porém, estão levando a resultados consideravelmente diferentes. Qual deles você passaria para seu chefe? E agora pense essa divergênvia juntando não dois meses, mas 36… 60 meses!
A saber: no cálculo 2 temos de fato o ticket médio do período. E se abrimos pedido a pedido e fizermos a média dele, dará justamente R$5375. Já o cálculo 1 é a média das apurações mensais dos tickets médios. Em bom português, a média das médias – algo que, segundo os entendidos de matemática e estatística, não é algo muito bem visto, embora muitas pessoas o façam, até por não terem acesso aos dados “brutos” para calcular de outra forma.
Também me incluo
Aliás, também me incluo nos que estão suscetíveis a erro. Dias antes de escrever este artigo, fiz o ETL para criação de um dashboard estratégico de marketing digital, mostrando a evolução de um site, usando dados brutos da API do Google Analytics e Power BI. O problema é que, quando se trabalha com dados direto da fonte, se lida com métricas cuja nomeclatura nem sempre é clara. Na API do GA4, por exemplo, existem as métricas “Defaut Session Channel group” e a “Primary Session Channel Group”. Nomes bem parecidos. Mas se você tem um conhecimento intemediário em GA4 sabe o que é Session Channel Group e sabe que ele é diferente de User Channel Group. Então, se viu qualquer métrica em uma lista com Session Channel Group, ficaria tranquilo em usá-la em seus dashboards e cálculos, certo?
Também achei isso. O problema é que a forma com que os dados são gerados em “defaut” e “primary” nas duas métricas são bem distintos. E eu não sabia disso! Resultado: fiz uma série de cruzamento de dados usando um indicador equivocado, de modo que o erro se multiplicou em vários outros KPI’s. Por sorte, eram indicadores que também existiam no Google Analytics. Então, logo percebemos o erro e corrigimos o cálculo. Porém, se não tivesse outra fonte de consulta, como saberíamos?
(off topic: Embora não seja esse o caso, vários profissionais de Data Analytics já notaram que um mesmo indicador pode aparecer com um valor no Google Analytics 4 e outro no Looker Studio, embora o Looker seja uma ferramenta do próprio Google e com integração direta ao GA4. Vai entender…)
Meus 2 centavos de contribuição
Por fim, compartilho algumas regras de ouro que utilizo em tudo o que se refere a dados:
1 – Os termos/conceitos precisam estar claros para todos
É preciso saber a que se refere as métricas que estão sendo trabalhadas. São vendas faturadas ou vendas pagas? O que é sessão e como ela se diferencia de page view?
2- Os cálculos precisam estar claros
Como se está chegando a uma métrica? O cálculo é correto? Algumas pessoas consideram ROI como resultado da divisão do valor vendido sobre o investimento. Outras, primeiro subtraem do vendido o valor do investimento, para depois dividir. E isso gera resultados bem distintos. Por isso é preciso usar os mesmos critérios.
3 – Os tratamentos de dados precisam ser conferidos
Será que nenhum erro foi cometido na geração de um SQL? Nenhuma informação foi perdida ou distorcida no Power Query? A lógica do DAX está certa? Muitos equívocos podem passar batido. E , para percebê-los, o ideal é uma segunda pessoa conferir o que foi feito – de preferência várias, se a informação for muito relevante.
4 – Confira em outras fontes
Se disponível, vale checar a informação em uma segunda fonte, nem que essa fonte seja o dado bruto. E refazer essa checagem sempre que alguma pequena mudança for feita no processo de tratamento de dados. Pois um dado que é confiável hoje, amanhã pode estar distorcido. E ninguém perceber (a contabilidade das lojas Americanas que o diga!).
Ps: nem cheguei a entrar no assunto relacionado a problemas de rastreamento no marketing digital, em tempos de LGPD e bloqueio a cookies de terceiros (no Safari e agora no Chrome) e a insegurança que isso gera em relação à precisãos de dados. Mas esse assunto é tão complexo que resolvi tratá-lo a parte.
Diogo Honorato – possi quase 16 anos de experiência em marketing, atuando no digial desde a febre dos blogs. Atuou em agências e empresas de segmentos como educação, varejo, indústria e franquias.